首页 > 文档
如何为社交feed场景设计缓存体系
- 2024-05-30
- 1311 ℃
Feed 流是很多移动互联网系统的重要一环,如微博、微信朋友圈、QQ 好友动态、头条/抖音信息流等。虽然这些产品形态各不相同,但业务处理逻辑却大体相同。用户日常的“刷刷刷”,就是在获取 Feed 流,这也是 Feed 流的一个最重要应用场景。用户刷新获取 Feed 流的过程,对于服务后端,就是一个获取用户感兴趣的 Feed,并对 Feed 进行过滤、动态组装的过程。
接下来,我将以微博为例,介绍用户在发出刷新 Feed 流的请求后,服务后端是如何进行处理的。
获取 Feed 流操作是一个重操作,后端数据处理存在 100 ~ 1000 倍以上的读放大。也就是说,前端用户发出一个接口请求,服务后端需要请求数百甚至数千条数据,然后进行组装处理并返回响应。因此,为了提升处理性能、快速响应用户,微博 Feed 平台重度依赖缓存,几乎所有的数据都从缓存获取。如用户的关注关系从 Redis 缓存中获取,用户发出的 Feed 或收到特殊 Feed 从 Memcached 中获取,用户及 Feed 的各种计数从计数服务中获取。
 下载完整资料
下载完整资料
 点击分享文章
点击分享文章
上一篇:如何为秒杀系统设计缓存体系
下一篇:如何用 JS 实现各种数组排序
相关内容
 面对海量数据,为什么无...
面对海量数据,为什么无...- 利用Python进行数据分析
- 25年政治考研徐涛全程辅...
 3 大主流系统框架:由浅...
3 大主流系统框架:由浅... C#并发编程 经典实例
C#并发编程 经典实例 实用人体解剖图谱 躯干...
实用人体解剖图谱 躯干...- 考研英语阅读方法论
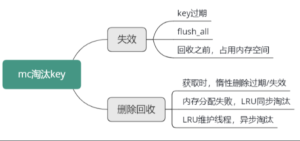 MC如何淘汰冷key和失效key
MC如何淘汰冷key和失效key
-

像计算机科学家一样思考(C++版)
2024-05-28 1139
-
初高中教材电子版
2024-08-19 1322
-
内存检查:多种类型的内存泄漏分析方案
2024-05-24 1515
-

Dubbo 过去、现在以及未来
2024-05-28 1297
-
ort 排序方法的实现原理
2024-05-24 1443
-
教师资格考试普通话水平测试
2024-08-19 1164
-
中医医师执业资格考试-内科学
2024-06-18 1397
-
Spark大数据处理:技术、应用与性能优化
2024-05-24 1378
-
小学教师资格考试综合素质模拟卷
2024-08-20 1007
-

初中文言文全解一本通
2024-07-13 1462
文章评论 (0)
- 这篇文章还没有收到评论,赶紧来抢沙发吧~